%20(1).avif)
When I joined my team as a researcher, I walked into what looked like a researcher's dream. Every team was talking to customers and gathering important information about their needs and problems. Data was flowing.
But no one stopped to analyze it, draw conclusions, or turn it into actionable insights. Despite the volume, all this information wasn't actually helping us make better decisions. When the team needed to decide on priorities, someone would remember a conversation they had with a user two weeks ago.
Does this sound familiar?
I was hired as a researcher to make sense of this chaos. My story isn’t unique - this is the new reality for researchers in democratized organizations.
In this article, I'll share my personal journey of navigating this shift and what I learned along the way: how to actually make democratized research work, what it means for the researcher's role, and the practical steps that turned scattered data into insights that drove real product decisions.
What democratization looked like in practice
Research democratization in organizations is now a fact. According to the "UX Research Democratization: 2025 Survey Report" from Great Question, 84% of researchers work in democratized environments—meaning environments where non-researchers also conduct research.
In my organization, each team had established its own research practices. Here are examples of the types of data each team collected:
- Marketing used analytics tools to discover the most popular sections on our website and identify topics that resonated with our target audience. For example, they noticed that blog posts about workflow automation, a feature we were heavily investing in, got minimal engagement.
Meanwhile, articles about connecting email inboxes to the tool were getting significantly more traffic and time-on-page. This was critical information: users weren't interested in advanced automation yet. They were struggling with basic functionality like email integration.
But the product team had no idea—we were planning to double down on workflows while ignoring the problems users were actually facing with core features!
- Sales investigated why deals fell through. They discovered a pattern: prospects often chose competitors because we didn't offer dark mode. To the product team, this seemed trivial compared to the sophisticated automation features we were building.
But Sales understood the context we were missing—users spent many hours per day in the tool, and dark mode wasn't a nice-to-have, it was a basic expectation. There were many insights like this buried in sales notes that never made it to roadmap discussions.
- Customer Success collected data from chat conversations to identify recurring questions and problems. They also conducted exit interviews with customers who decided to cancel, storing them as recordings and transcripts.
They were constantly exposed to what frustrated users, what confused them, what made them consider leaving. If we had brought all this data together in the product process, we would have quickly realized that advanced automation wasn't the most discussed topic—it was basic things like email inbox configuration.
Multiple sources, different formats, all potentially useful- not just for the teams collecting them, but especially for the team developing the product.
Looking back, it all seems obvious now!
The risk: data without insights
Thanks to every team's engagement in understanding customer needs, we had massive amounts of data. Yet our product roadmap was still based on my research alone—formal studies that I, as the only researcher, couldn't run nearly enough of.
Meanwhile, Marketing saw what topics were relevant. Sales heard why prospects chose competitors. Customer Success dealt with real user frustrations daily. But none of it was influencing what we actually built. We weren't extracting valuable insights from any of this.
What a waste! 😱
Single-source bias: when anecdotes start driving decisions
I often heard "Hey Weronika, I have a new insight from a customer conversation," but that's still just data. One conversation isn't a pattern yet.
It's hard to remember every individual customer statement and context. This can lead to anchoring on specific data points. For example, if I personally ran a demo and the customer told me they're missing an AI chat function, I might give that particular piece of information special weight and treat it as an "insight," while ignoring everything else.
On top of that, when teams kept collecting data to themselves, the organization couldn’t build a coherent picture or move in a clear direction. No wonder—such a large volume of information without additional synthesis or interpretation can simply become overwhelming and hinder decision-making instead of facilitating it.
How my role as a researcher changed because of democratization
To prevent all this data being wasted, someone had to bring it together, analyze it, and synthesize it into meaningful insights. And who better to do that than a researcher?
This is exactly why the product manager started looking for a researcher to join the team. My job was to figure out what we already knew and where we stored different pieces of information. To analyze them together, I needed to create one place to gather everything—in other words, build a research repository. (You can read about how I created that research repository in this article.
So how did I actually gather all this data from different teams?
I started with internal research - interviewing representatives from each team to understand what data they had and how they collected it. Once I knew what existed, I kept teams informed about what research questions we were currently exploring.
They could then point me to relevant data they'd already collected on that topic. It became a two-way street: my systematic investigation paired with ongoing collaboration.
Then came the repository itself. I couldn't migrate everything, all the analytics dashboards, every Jira ticket—that would've been impossible. I focused on gathering data around the most important topics we were trying to solve, and asked teams to add significant new information directly to the repository and…it didn’t work.
The importance of automatization
Asking teams to manually input data into the repository in a specific format was too time consuming for them. They had their own jobs to do.
The breakthrough came when I stopped trying to change how teams worked and instead focused on automating the connection between their existing workflows and the repository.
Believe it or not, AI solved the format problem for us. Tools like Survicate’s Research Hub turn messy, unstructured feedback from multiple sources into structured insights automatically.
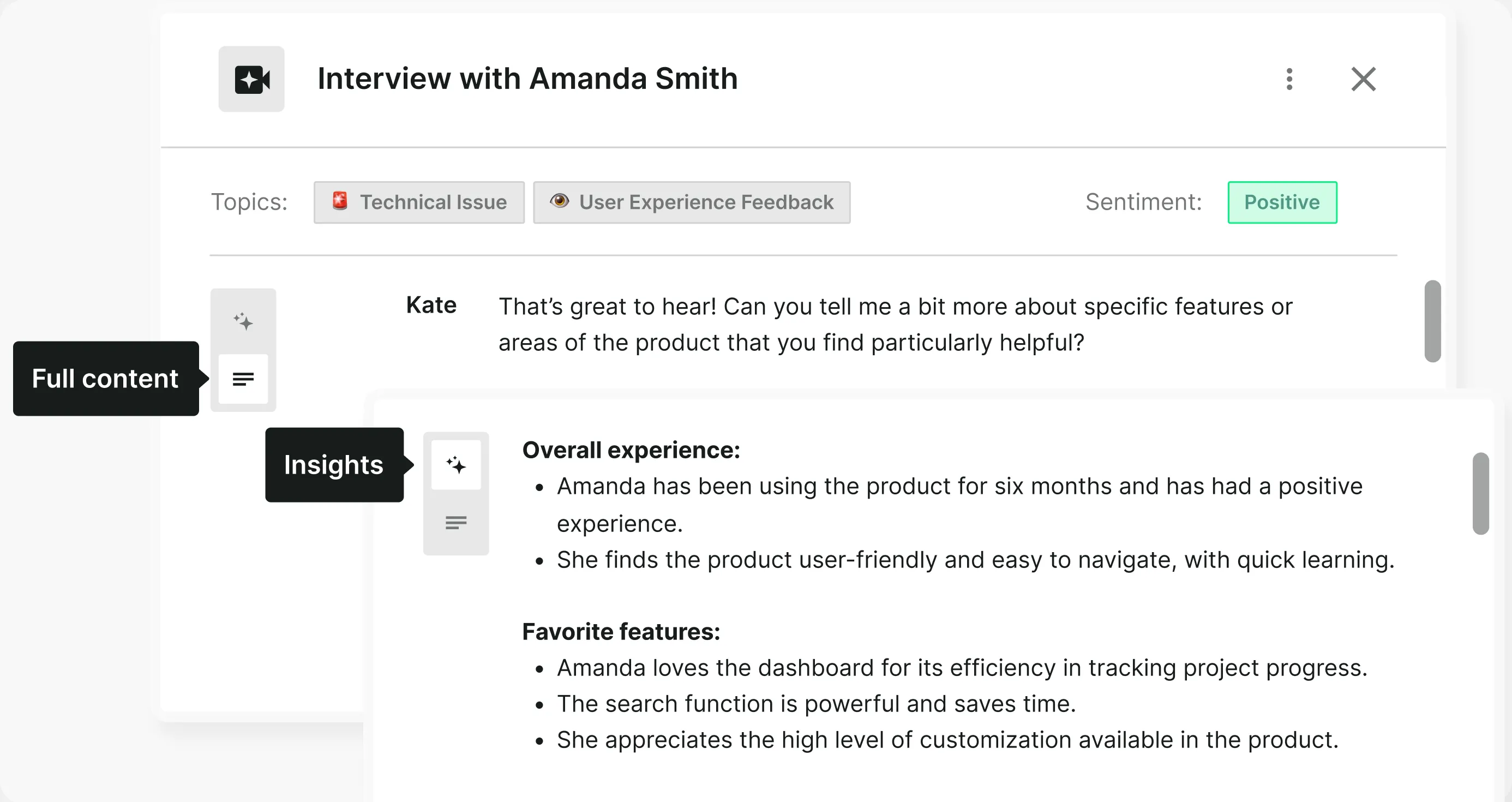
The real advantage is scale. AI can process hundreds of open-ended responses, sometimes it mislabels a comment, but so does manual coding. Even if I had weeks to analyze everything myself, I’d still miss patterns across sources. AI doesn’t get tired, and it keeps working as new feedback flows in.
And in most teams, the alternative isn’t better categorization. It’s no categorization at all because there’s simply no time.
AI takes data in whatever format it already exists, so teams can keep working exactly as they had been.
From data collection to actual insights
Once the repository existed and stayed updated, my role shifted to synthesis. I became the person connecting dots across teams.
Every week, I published the most interesting insights to a dedicated Slack channel to make people curious. I created short video clips showing actual user feedback and shared them in our weekly product meetings.
Quarterly, I'd present patterns that emerged across all company data: which problems came up most frequently, which user complaints appeared in Sales calls, CS tickets, and Marketing surveys simultaneously.
From stored data to proactive analysis
This wasn't just about storing data. It was about making sure the product team could query the repository on specific topics instead of relying only on formal research studies I ran.
We could still do deep dives on individual questions, but we could also spot trends, especially with AI analysis surfacing patterns we might have missed.
For example, support tickets could be automatically exported to Excel and analyzed with AI tools. Suddenly our roadmap started reflecting reality.
Our product betas aligned with actual user needs. We stopped fixating only on advanced features and started addressing the basic frustrations that turned out to matter most.
How the culture shifted
Thanks to this change teams started feeling like we were all working toward the same goal. Sales, CS, and Marketing saw that Product was actually listening to what they'd been saying all along. Their frustration—"we understand this but the rest of the organization doesn't"—decreased.
They became more willing to contribute because they saw their input genuinely influencing decisions. When Sales mentioned that dark mode was killing deals and we actually prioritized it, they felt heard.
My role became about validating what teams already knew and spreading that knowledge across the organization, making sure it wasn’t forgotten.
But equally important: making sure we didn't fixate on single data points. I was the check against someone saying "a customer mentioned X in a call yesterday" and treating that as gospel. Patterns, not anecdotes.
These are the challenges you’ll face
This sounds like a lot of work for a researcher—and it is. Analysis and synthesis are time-consuming, which naturally means less time for conducting new studies.
Data collected this way won't meet the methodological rigor of carefully planned research. People sharing it might attach their own interpretations instead of presenting raw observations.
But as researchers, especially in small teams, we wouldn't be able to gather these volumes on our own. Data from so many contexts helps create a more realistic picture, even if it's imperfect.
And sometimes you discover things you didn't know to look for—like users abandoning your tool because they don't understand how to use it, not because of missing features.
Here are the main challenges I faced:
Problem: Teams won't adapt to your format
Don't expect Sales, Marketing, or CS to change their workflows to fit your repository vision. The burden is on you to understand how different teams work and automate the grouping and analysis of data from their existing sources.
Problem: Inconsistent data quality
You'll get data in different formats, with different levels of detail and rigor. Accept this. It's still valuable data from real users. Ignoring it because it's not "research-grade" means leaving insights on the table.
Problem: Manual analysis doesn't scale
Without tools that extract insights from large datasets, you'll either never create the full picture or spend 40 hours a week reading data—leaving no time for new research. When you're a solo researcher, automation and AI aren't optional. They're mandatory.
Set specific analytical goals
To avoid drowning in data, set concrete analytical objectives for specific weeks. Explore data according to current needs and use those insights to continuously update the roadmap.
When AI surfaces an interesting pattern, dig deeper into the source information. As you collect more data and understand the product better, you'll get better at verifying automated insights.
The question isn't whether more data is inherently better. It's whether you have the capacity to turn that data into insights.
More data is only valuable if you synthesize it properly. With it, you're building a more complete understanding of your users than any single research study could provide.
Democratized research brought me closer to the business
In just 12 months, my role as a UX researcher changed completely. I now split my time between extracting insights from existing data and conducting focused research studies. Both are essential.
You can't passively wait for information—sometimes you need targeted research. But you also can't ignore the data already flowing through your organization.
I'm closer to the business now because I'm connected to both: continuous signals from democratized research and deep dives from studies I design myself.
The democratization of research is happening whether we design for it or not. We can let data pile up unused, or we can build the structure to make it genuinely useful. The choice is ours.
And maybe this is the role shift all of us UX researchers need to embrace: no longer owning all research or insights, but taking the lead in turning those same insights into meaningful business change.








.png)




.svg)

.svg)