%20(1).avif)
TL; DR
- Traditional repositories often fail because they’re hard to search, maintain, and use without constant support from a researcher.
- AI-powered tools like Survicate solve this by eliminating tagging, enabling natural language search, and offering instant access to relevant insights.
- Teams across the company — from product and marketing to design and leadership — can independently explore research and act on it.
Traditional research repositories promise to centralize insights and support better decision-making, but they rarely live up to that promise.
In my experience, even a structured and well-tagged repository quickly turned into a a silo of knowledge that looked organized but no one actually used it. It was hard to search, disconnected from the team's daily work, and overly dependent on me to interpret or resurface insights. The system itself became the bottleneck.
The real breakthrough came with AI-powered tools. They removed the need for manual tagging, enabled natural-language search, and allowed the team to work with research data without requiring expert help. What once felt like a static archive turned into a living knowledge base — accessible, searchable, and actually used.
Let’s explore why traditional repositories fall short — and how AI can finally make them work.

Why do traditional repositories fail?
Research repositories serve to gather and organize knowledge from research activities: interviews, surveys, usability tests, and any other valuable insights about your customers.
Ideally, they serve as a single source of truth: a place where anyone in the organization can access what’s already been learned and use it to make smarter, faster decisions.
Traditional repositories sound good in theory as a centralized, searchable home for research. But in practice, they come with a set of challenges that make them hard to maintain and even harder to use.
Problem 1: Manual tagging takes too much time and effort
In traditional repositories, tagging is the main way to organize knowledge and make it searchable. If you want to quickly find all notes related to "onboarding" or "pricing," you rely on consistent tagging. But this requires someone to build and maintain an entire system of labels that reflects your product, research goals, and team language.
I spent hours defining categories, setting up tagging rules, and retroactively updating older notes. Even with some AI-generated suggestions, I still had to review and fix things manually.
The process was tedious, error-prone, and never-ending. A single missed or misapplied tag could mean an insight was effectively lost. Over time, search results became unreliable, and the team lost confidence in the system.
Problem 2: Only the creator understands the system
Because I built the tagging system, I understood it. But no one else did, at least not fully. What seemed obvious to me often wasn’t to others. Teammates had to guess how I’d labeled things or come to me for help translating their questions into tags.
In theory, they could find answers themselves. In practice, they’d ping me asking: “Which tag should I use to find feedback on onboarding friction?” The knowledge was there, but locked behind my logic. As a consequence, fewer people used the repository, and more relied on me as the gatekeeper.
Problem 3: Raw data doesn’t translate into clear answers
Even when someone managed to surface relevant notes, they were often staring at a wall of raw input—quotes, screenshots, or disconnected bullet points. Turning that into insight still required time and context. And once teammates had the material, they often didn’t want to (or couldn’t) invest the time to interpret it. Instead, they turned to me for summaries.
And while it’s often a good thing for researchers to guide interpretation, in organizations where there's only one researcher, this model quickly breaks down. There simply isn’t enough time to synthesize everything, which means valuable knowledge goes unused.

What should a modern research repository really do?
After wrestling with the limitations of a traditional research repository, it became clear that I needed something fundamentally different — a solution built for the way people actually work and search for information.
To remove barriers to access and truly democratize research, the system I was looking for had to be:
- Tag-free: No more manually maintaining a fragile taxonomy.
- Fully searchable: Across interviews, notes, decks, and spreadsheets, regardless of format.
- Natural-language friendly: So team members could ask specific questions and receive direct, relevant insights.
- Self-serve by design: People should be able to find and interpret insights on their own, without always relying on a researcher to step in.
In short: we needed a practical, time-saving way to access research — one that would help teams get to insights faster and support smarter decisions without extra hand-holding.
How does AI remove friction from using research?
To find a better way, I tested different AI-powered tools for building a research repository. One of them was Survicate.
Survicate’s research repository consists of two connected components: Research Hub, where you can explore topics and group feedback into insights, and Research Assistant, a conversational interface that lets you interact directly with your uploaded data using natural language queries.
To actually solve the challenges of traditional research repositories, any AI-powered alternative needs more than just automation. It should be built around how people naturally search, think, and work with insights.
Here are the core capabilities that make an AI-powered repository simple to use and truly present in everyday decision-making.
No need for manual tagging
AI-based tools no longer require hours of manual tagging to make data usable. Instead of manually categorizing every note, AI processes natural language directly and clusters insights automatically. This is a game changer: we can now work with and interpret research using raw inputs, without any setup work.
It means we don’t waste time on maintaining a tagging system or risk losing insights due to human error. And it means we can handle much more data, much faster.
That’s exactly how Survicate works. In addition to analyzing native survey results, you can upload notes from other sources. AI scans the content, identifies themes, and groups insights, no tagging required.
Helps the team draw conclusions
Sometimes, as a researcher, I just can’t be everywhere at once. When teams need answers fast, there’s no time to run a full research cycle. AI helps bridge that gap. It not only gathers all the relevant files and feedback on a given topic, it also summarizes what they actually say, saving time and guiding the team straight to the point.
In Survicate, team members can monitor topics that are important to them, such as "Feature Requests",and the tool will pull in relevant notes and create an insight that summarizes all this knowledge.
Questions can be asked directly
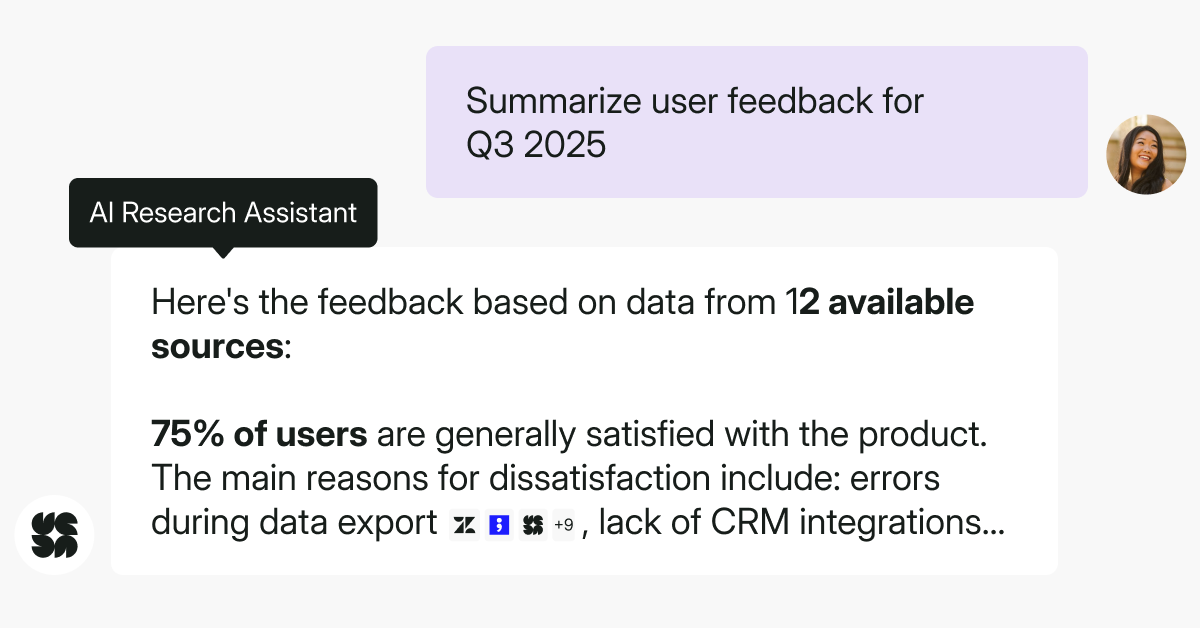
Instead of learning how to search a system, team members can just ask research questions like they would in a conversation. There’s no need to learn a system or guess keywords, just type what you’re curious about.
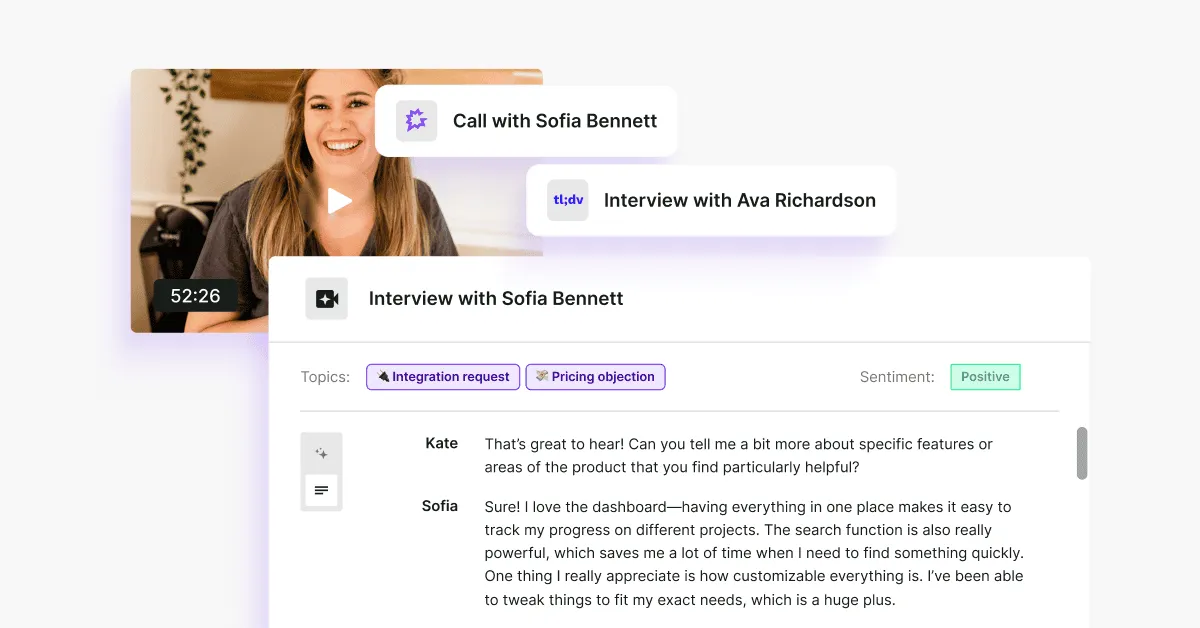
In Survicate, this is what the Research Assistant enables. Users can ask plain-language questions like “What are the top issues users face during onboarding?” and receive answers grounded solely in the survey data. The Assistant processes natural language, scans the relevant responses, and delivers synthesized insights.
Every answer comes with a direct source or citation
We all know that AI can make mistakes and that context matters. That’s why it’s essential that every AI-generated answer in a research repository includes clear links to the original sources it’s based on.
Survicate’s Research Hub and Research Assistant both do exactly that. Each insight comes with supporting notes and shows how many sources it draws from. This makes it easy to verify claims, dig deeper into the data, and explore full context, without relying solely on a summary.
This builds trust in the results and speeds up access to related data. Instead of guessing or digging, the team can quickly verify insights, understand the context, and move forward with confidence.
Searches only within your files
When working with AI, one of the most important features is control, especially over what data the system references. Unlike general-purpose tools like ChatGPT, a good AI-powered repository should work only within your selected files to avoid.
In Survicate, this is built-in by default. Insight Hub analyzes only the data you upload or collect — surveys, interview transcripts, PDFs, decks — and allows filtering by source. That means you never have to worry about the AI hallucinating based on outside information.
It also makes prompting easier. You don’t have to write long instructions or warnings; just ask what you need, knowing it’s grounded in your actual data.
How different teams can use an AI-powered repository
Once in place, an AI-powered research repository can unlock value across the organization, far beyond the research team. Here are practical ways different departments can make the most of it.
Product Management
- Explore new opportunities: PMs can explore topics in the repository to understand what customers are really talking about and how often. This helps generate ideas rooted in actual data.
- Validate product hypotheses: If a PM has a strong hunch after a user interview, they can easily check whether similar feedback appears elsewhere in the repository. This helps avoid acting on isolated opinions.
- Prioritize the roadmap: With always-updated insights, product decisions can be grounded in real, current feedback. It’s a way for research to actively shape the roadmap, which is every researcher's dream.
Marketing
- Plan campaigns and webinars based on real needs: Marketers don’t have to rely solely on new surveys or guesswork. By exploring existing insights on topics that matter to users, they can create more relevant messaging and detailed campaign outlines.
- Support competitor analysis: Customers often mention alternative tools in different contexts. An AI repository allows marketing to quickly surface these mentions and better understand what users value in competitors — a strong complement to traditional desk research.
Leadership
- Assess the state of knowledge: Executives and managers can use the repository to explore broad strategic questions and get a high-level view of what the company knows — and what it doesn’t. It helps surface blind spots and shape priorities for future research or product strategy.
Design
- Reference existing feedback in UI/UX work: Not every flow gets its own dedicated research. Designers can use the repository to explore scattered signals and adjust their designs based on feedback collected across various contexts.
While it won’t replace human synthesis or interpret emotion-heavy contexts like usability testing, an AI repository dramatically reduces the time and friction involved in finding and using research.
The Limits of AI – and Why It Still Works
AI isn’t perfect, and it doesn’t need to be. Even the best systems can make mistakes, misunderstand questions, or oversimplify nuance. That’s why the foundation of any AI-powered repository should be your internal data: the actual transcripts, surveys, and notes you’ve gathered from real users.
Transparency is key. Every answer should be traceable to its source. If you’re using AI to summarize or extract insights, it must also point to the original quote, document, or response so you can verify the context yourself.
Importantly, AI doesn’t replace the need for human analysis, it just removes the mechanical work that gets in the way. No need to tag, sort through spreadsheets, or manually reconstruct context. It’s also a great solution for surfacing insights when there’s no room for dedicated analysis on every topic, especially in smaller organizations where there’s only one researcher.
What matters most is understanding your users and making better, faster decisions grounded in their actual needs and feedback, not guesswork or memory.
Turn Your Repository Into a Tool for Action
A research repository isn’t just a storage system — it’s a tool meant to help people make better, faster decisions based on what we’ve already learned. When it becomes too complex, too slow, or too dependent on one person, it fails in that purpose.
If your research repository feels like it’s gathering dust, don’t wait for the perfect structure or tagging system. You don’t need to overhaul everything overnight. Begin with what you already have.
Upload a few high-value documents, connect the tools you already use, and encourage your team to start asking real questions.
By removing friction and making research easier to access, AI-powered repositories help break down silos. They ensure that knowledge flows, across departments, across roles, and into daily decisions. That’s how you make research not just visible but also valuable.
This is exactly what Survicate delivers. It removes the friction of traditional repositories and makes research truly usable, not just stored. If you're ready to spend less time tagging and more time acting on insights, there's no better moment to start. Sign up for a free trial today and see how quickly your team can find answers, without waiting on you.














.svg)

.svg)

